Using Amazon Timestream to Manage Your Analytics
In our current day and age, data is everywhere. From clickstream data collection such as storing an event when a user clicks on a link, to storing the amount of time they spend on a particular web page, it is small but plentiful. In fact, this data has a unique name: time series data. Time series data is a group of data points taken over time. This type of data includes weather, stock prices, monthly subscribers; any data whose points have a unique timestamp attached to them can be considered time series data. While generating these kinds of data is easy to achieve, depending on the scale, storing this data is another challenge. This is where Amazon Timestream comes in.
What is Amazon Timestream?
One of the new services from AWS (Amazon Web Services), Amazon Timestream seeks to provide a simple, scalable, and affordable solution for storing time series data. Released on Sep 30, 2020, this non-relational database seeks to make it easy to store and analyze time series data of any scale, whether it is thousands of records or millions. Built as a serverless option, querying, writing, and storage capacity scale independently without needing to provision the capacity. One notable feature is storage tiering where Amazon Timestream handles the data lifecycle management of all data stored in its database. This includes moving old data to slower storage or even deleting the data and handling the whole archival process. Another feature is that Amazon TimeStream has built-in analytics for time series data such as window functions and even complex data types such as arrays.
Why use Amazon Timestream?
You should use Amazon Timestream if you have a large amount of reads or writes of time series data and want a low-cost method of storage, need to query large sums of time series data, want an easy and manageable solution for controlling the data lifecycle management of the data you are storing or wanting to offload data collection to keep your application separate from analytic data.
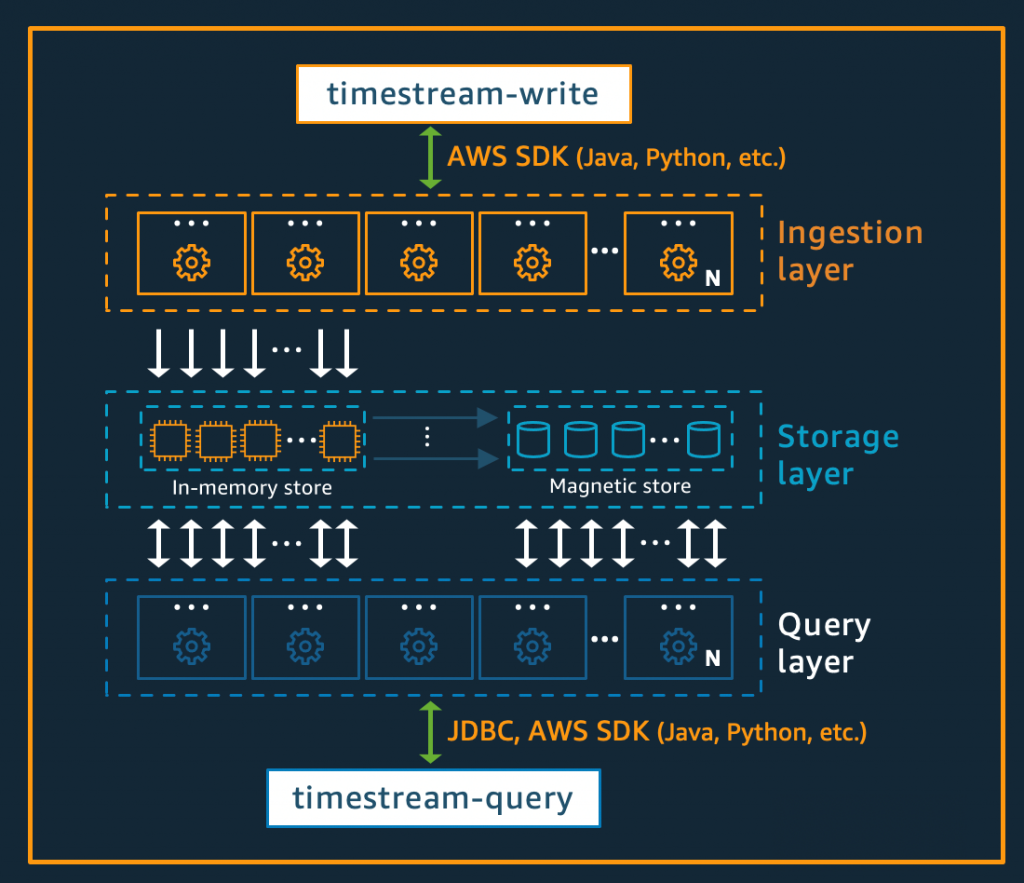
When it comes to reading and writing time series data, Amazon Timestream is a great solution when the data you are generating is small but frequent. Amazon Timestream can handle billions of records daily in both reads and writes. Having a large amount of reads or writes coming into a database not designed for time series data can severely bottleneck it, harming the experience for other data stored. For example, if you share time series data with a low-end MySQL database, if most of the writes are coming in from data collection, this leaves little room for querying and writing other data.
Amazon Timestream can also scale with your collection needs. Whether you get a sudden spike of records needing to be written, Amazon Timestream handles this with a high-speed ingestion storage designed to handle high throughput writes. Once this data is in Timestream, it is eventually transferred to a read optimized storage medium to save on costs which handles cases of high-read activity.
With Amazon Timestream you also can set clear-cut data management with a few clicks. Only need the data for a short window of time? You can set the data retention for the high-speed write storage to an hour with the magnetic storage down to 1 day. These retention periods can be raised to as high as 12 months for fast storage and 200 years for slower storage.
Another reason to use Amazon Timestream for data collection and retention is to clear up resources for your application. As your data collection scales up, certain resources may be used up just from writing the amount of data being collected. Using a separate database designed for data collection frees up your main application database for storing and querying important core data rather than being bottlenecked by writing time series data.
Drawbacks
While Amazon Timestream is great, it also comes with drawbacks. For starters, this is one of AWS’s newest services. The feature set is small starting off and it may lack the bells and whistles of other services such as Google Analytics which has a more robust displaying and collecting of data.
Another example is that the data has no schema structure. As data comes in, a schema is made on the fly to accommodate new columns that did not exist before, likewise, data can be dropped, and the schema evolves with it. This is great when you want to add new types of data or change up the schema quickly, but this requires extensive tooling to handle querying and interpreting the data.
The last major drawback is the unoptimized pricing scheme for small reads. If you have a heavy read workflow, Amazon Timestream charges for each query request with a minimum amount of data required to be charged. This can add up fast if your application needs to write lesser amounts of data but reads from it heavily.
Our Use Case
We decided to use Amazon Timestream for our analytics data in one of our projects for three main reasons: our need to scale at will, the affordable pricing, and the offloading of resources.
Our main problem was having a high-write, low-read style of analytics. We wanted to record analytics events for time a user spends reading a question, when they send a message to another user, changes they make to a text field, and so on. This type of data generates fast as the number of users grows, so we need a highly ingestible system. Amazon Timestream provides this, as their database is built to handle writes faster than our needs. This is good; when the application grows its user base, writing will scale with it.
With the number of writes we will be performing, this also raised concerns about our current database limitations. We can only scale our main application database so far before costs become too large to scale up. Luckily, with Amazon Timestream, we can use this database to offload all the writing and reading to a separate scalable database, freeing our main application database for a different type of workload.
Finally, Amazon Timestream costs appealed the most to us. Allocating a write-intensive MySQL database via AWS’s RDS (Relational Database Services) costs way more than Amazon Timestream, not only that but we would need a scalable interface as our data collections need to grow. Even when data collection has been happening for years, the cost of using Amazon Timestream is less than the cost of allocating another database. We estimated the cost of using Amazon Timestream at around $20 a month after 5 years of storing data, while a whole new RDS database costs around $50-$100 depending on the tier.

Alternatives
Amazon Timestream is not the only time series database solution out there for the type of problem we had. Google Analytics was another option we explored. They have a free tier for up to 10,000,000 writes per month, but we decided against them as there is less control over how the data is stored. Amazon Timestream also has specific features like Scheduled Queries which we may want to use in our project one day. A solution like Google Analytics is well suited for those in the Google Cloud ecosystem and wanting a simple extension.
We have considered using DynamoDB, another AWS database solution, as Dynamo is also good at handling high-write throughputs, as well as efficient queries. Due to the nature of time series data, the partition would have to be on time. However, data access patterns would make querying on this database inefficient; either the time partitions will get too large, or we will have too many partitions to query. This solution would be better equipped for handling simple queries on time, but our access patterns are more complex.
The last alternative we explored was just adding another table to our current MySQL database. Since we have a large influx of writes, we would need to upgrade our database instance to handle such a quantity of writes. However, even with upgrading, the number of writes would still most likely hammer the database, slowing down other important application reads and writes. This solution would be better suited for smaller, infrequent, more consistent streams of data.
Conclusion
Amazon Timestream has given us an easy, scalable, fast solution for storing and querying time series data. With its quick setup, affordable scaling, and fast performance, Amazon Timestream may be your next choice for storing time series data.
 Strategy for Modernizing Monolithic Applications
Strategy for Modernizing Monolithic Applications
 The "Frankenstein" Cloud Software Application
The "Frankenstein" Cloud Software Application