Custom Authentication with Flask and AWS API Gateway
We already have a lot of apps that run in the AWS ecosystem and recently we’ve started to build more and more serverless applications, specifically serverless Python apps like the one showcased in our case studies. Many of these applications use AWS Cognito or other prebuilt solutions for authentication but those approaches have pros and cons. Sometimes you need the flexibility of a custom authentication approach. This article provides an overview of custom authentication with Flask, specifically serverless Python applications running in AWS. While presented broadly, this approach contains a few semi-modular components that could be adapted and used in a wide variety of differing setups.
What we have is a Flask application that is deployed with a serverless framework, which runs in an AWS Lambda behind Amazon API Gateway. Authentication is handled by a second Lambda, an API Gateway authorizer, which issues and validates OAuth2 tokens. Those tokens are stored in Amazon DynamoDB and are based on token scopes and grants defined with Authlib.
DynamoDB
DynamoDB is AWS’s fast and scalable NoSQL document-oriented database. The first thing you really need to know about DynamoDB is that it’s weird. The concept of a NoSQL, or non-relational, database is nothing new. But, when compared to similar systems, modeling data in DynamoDB can be pretty funky and the service as a whole has a bit of a learning curve. That doesn’t mean it’s bad, it certainly has its place. When AWS says fast and scalable they really mean that. And everything about this database is built with that specification in mind.
In a relational database, if you know that you will sometimes need values from multiple tables returned in a single query you connect the tables with a foreign key so that you can perform a join operation to combine records from both tables into a single result set. In DynamoDB this isn’t possible. Unfortunately, the join operation isn’t very fast and it certainly isn’t scalable. As tables grow in size, joins become increasingly expensive. So AWS said “no thank you” and completely removed any specialized non-scalable query operations from DynamoDB’s design. The official AWS documentation for DynamoDB advocates for single-table design. Instead of using pesky queries to try and join related data together at read-time, you just keep all the data in the same table to begin with. After all, you’ll never need to query data from multiple tables if you don’t have multiple tables. That being said, it is possible to have multiple tables in DynamoDB and you can link them together with global secondary indexes and perform complex queries on them with scans. Unfortunately, these features can increase the cost and decrease the performance of your database, respectively .
To briefly sum this all up, DynamoDB trades the flexible query options of relational database systems for a more restrictive but much more efficient and highly scalable design. And this can be the perfect fit for a user authentication system because you generally only need a small number of tables and attributes stored for each user. It’s important that authentication is fast and performance isn’t reduced as the amount of users increases. In our app, we use DynamoDB to store client information in one table and user authentication, refresh tokens, and some other Authlib-related data in another.
Authlib
Authlib is a Python library made for building OAuth and OpenID Connect clients and servers. It’s a very extendable library as it’s built with low-level specifications that extend up to high-level integrations for popular frameworks and libraries. What this means is that if you are using something like Flask, Django, FastAPI, or SQLAlchemy you can simply import the necessary Authlib integration and you’re good to go. For our app, we use some prebuilt Flask integrations and SQLAlchemy mix-ins, but we were still able to easily build custom DynamoDB integrations from lower-level Authlib classes where we needed them.
As the Authlib docs say:
It is also possible to create your own grant types. In Authlib, a Grant supports two endpoints:
1. Authorization Endpoint: which can handle requests with response_type.
2. Token Endpoint: which is the endpoint to issue tokens.
We use token endpoint grants for our login and token refresh endpoints. But, they can also be used to define multiple custom login flows if your app supports them. An authorization endpoint grant is what you use to verify the validity of a caller’s authentication token and grant access to your resource server. Authlib gives you the option of defining custom scopes, things like User and Admin, that an authorization grant can use to restrict a user’s access to different resources. In our app, the grant/authorization logic happens in an API Gateway Lambda authorizer and, as mentioned above, all the auth data is stored in DynamoDB.
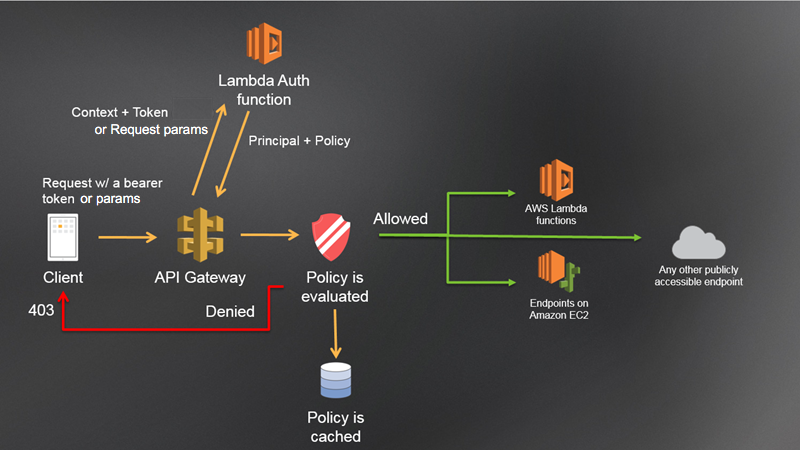
API Gateway Lambda Authorizer
API Gateway gives you the option of using a custom authorizer stored in a Lambda function to control access to your API. This is especially useful if you’re trying to keep your authentication server and API completely separate. Besides the inherent benefits of keeping your resource and authentication servers separate (independent scaling, ability to swap out authentication methods, etc.), API Gateway’s Lambda authorizers have policy caching options that can help you reduce the actual amount of authorizations logic performed by your server. If your app isn’t already running in API Gateway it definitely isn’t worth it to switch over just for this, as you can use any server as an auth server. But if your app is already running behind API Gateway the Lambda authorizer is a very convenient feature that you should probably take advantage of.
Our authorizer works by receiving the caller’s identity in an OAuth token, verifying the token with a call to DynamoDB, and then returning an IAM policy that will either give or restrict access to a given resource depending on the caller’s identity and requested resource. We can choose to cache these responses for a certain amount of time to keep from processing the same request from the same user multiple times. Returning an IAM policy is an unfortunate restriction of using API Gateway’s Lambda authorizers, as these policies can be finicky and complicated. In this case, the headache is probably worth it for the fine-grained access control given in return.
Good Fit for Custom Authentication?
This setup is great, if I do say so myself. It’s got all the buzzwords going for it – scalable, resilient, performant, secure, and extendable. But at the end of the day, it’s only good because it works well for us and for what we are doing.
On a scale of “bare-bones password login” to “ultra complex multi-flow login”, I’d say that custom authentication is the best choice at both ends of the spectrum, whereas a prebuilt service is good anywhere in the middle. You could argue that a prebuilt service works well at the simple end, but that’s a matter of choice. A simple password login takes minimal effort to create yourself with some open-source tools. A prebuilt service might still be slightly straightforward to plug and play, but it may come at the cost of flexibility and customization.
If you’re using some or all of the technologies discussed here, this set-up might be worth looking into. If you aren’t using any, then maybe not. As it is with everything in software development, every project’s and team’s needs are unique and varied. There is no one-size-fits-all solution.
 Strategy for Modernizing Monolithic Applications
Strategy for Modernizing Monolithic Applications
 The "Frankenstein" Cloud Software Application
The "Frankenstein" Cloud Software Application