Exploring Natural Language Processing Using GPT-2 and Slack
Artificial intelligence is the hot technology on everyone’s minds, and it raises a lot of important questions. What can it do? What should it do? Should we all be slightly afraid? I don’t know. As a custom software company, we often need to work with new (or unfamiliar) technologies. As a result, our developers are expected to learn on the fly. Artificial intelligence is one such area where there is so much to explore and so much yet to be explored. For our exploration, we looked for practical applications of AI in software. And where we landed was natural language processing.
To explore natural language processing, we need a large source of natural human language. And where better to find natural, normal humans conversing naturally and normally with each other than in the company’s Slack channels?
What is Slack
Slack is both an essential messaging platform and an absolute time killer. Thousands of messages are sent every day over Slack and messaging platforms like it. These tools were originally meant to bolster workplace productivity. Devious software masquerading around as “workplace productivity tools”… Who could have predicted the transformation of these services into the work-devoid, meme-filled hellscapes we see today? And what can we do about it? Alas, I digress. There is a plethora of communications within Slack that are well-suited natural language processing.
What is natural language processing
Natural language processing, a field concerned with the processing and analysis of natural language, has made significant advancements over the last few years specifically concerning machine learning-powered text generation models. These models, at the most basic level, are algorithms that predict the next word in a sequence of text (like the keyboard on your phone or the dropdown suggestion box on a search engine). Recently they have gotten much better at producing longer and more human-like text. For our purposes we will focus on a use case of the natural language model GPT-2. GPT-2 has significantly outperformed other unsupervised models on a variety of language modeling tasks. It can generate realistic continuations of input text which mimic the style and format of the input. An example of GPT-2’s abilities can be seen below.
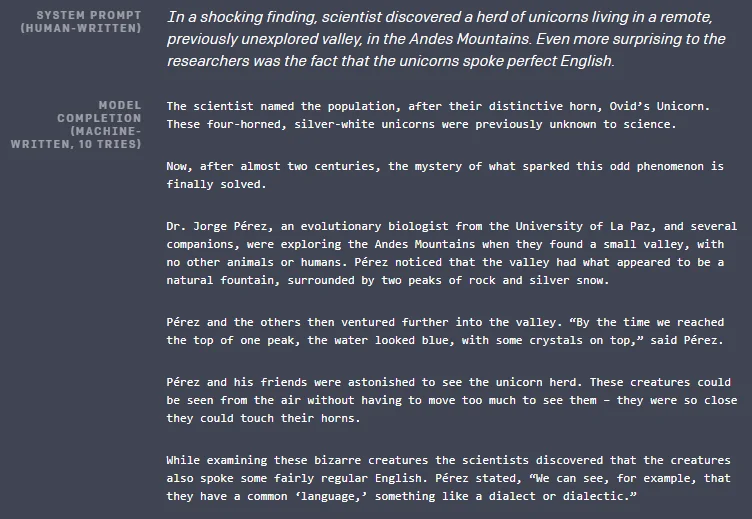
By fine-tuning GPT-2 on Slack data, I can run the model to generate fake Slack conversations. With this, I can fast-forward through a whole day’s worth of slack chatter in a matter of minutes by simply generating it myself. Why ask coworkers for technical advice when I could just use the model to predict their responses? Look at me saving the company precious time and resources…
Below, I ask the model for technical advice. The blue text is the input that I wrote and the rest is the GPT-2 generated response.
MADRONE: Should this variable be mutable? BILLIAM: i think so MADRONE: I'm not sure how to do this BILLIAM: so [value] = value
Very informative!
And here’s me planning a little light socializing with the help of the model.
MADRONE: What should I bring to the barbeque? JAZZ-MAN: I'll just get some mimosas and bring that MADRONE: tomcollins has a mimosas PIGEON LIFE-GIVER: im gonna put flan on it BILLIAM: my wife has some good caramelized oranges JAZZ-MAN: omg JAZZ-MAN: im gonna put flan on it MADRONE: I'll just make my own caramelized oranges PIGEON LIFE-GIVER: uncommon wisdom says to just make a waffle cone and put it on top of the caramelized oranges PIGEON LIFE-GIVER: theres some merit to that
What is GPT-2
GPT-2 is an unsupervised text generation model that OpenAI released in February 2019. It was trained on 40GB of internet data and is capable of “generating samples from a variety of prompts that feel close to human quality and show coherence over a page or more of text” . GPT-2 uses a transformer model, which you can read about here. Or, if like me, you’re not a data scientist, you can look at a much easier to follow explanation of transformer models here.
Originally only the small 124M, medium 355M, and large 774M models were released and the full 1558M 1.5B parameter model was kept private due to what OpenAI described as “concerns about malicious applications of the technology”. They basically said that the full-language model was so powerful that it needed to be kept private so that it couldn’t be used to create fake news. There’s no way to know if that was ever a legitimate concern or just a way to hype up their product. But, on November 5th, 2019 the full model was released to the public.
Fine tuning
Fine-tuning allows you to retrain the model on a much smaller dataset and generate text in the style and format of that data. To fine-tune GPT-2 you need to use the code in the fork of the GPT-2 repo, created by Neil Shepperd. The instructions in Neil Sheppard’s repo are fairly straightforward. And, fine-tuning can be run with a single command if you aren’t including any extra customization parameters.
The memory requirement to fine-tune the smallest GPT-2 model is more than even the beefiest of consumer-grade GPUs can handle. Fortunately, there is an easy solution via Google’s cloud computing platform where you can use a big strong Google GPU for free and run the code in your browser with a collab notebook. For best results, fine-tuning requires a relatively large (~10MB) dataset with consistent text formatting. If you’re trying to generate poetry and your dataset is 9MB’s of haikus and 1MB of movie scripts, the output text will reflect your poor data aggregation skills and punish you accordingly.
Depending on the data it might also be necessary to add a delimiter between key sections of text. Given the haiku example above, a delimiter would be needed between each haiku to give the model a recognizable pattern to identify. Without the delimiter, the model might recognize the dataset as one long poem or a long list of unrelated one-liners. The delimiter can be any string as long as it’s unique (or at least semi-unique) in the set; something like “<END OF TEXT>” would work fine.
Building the dataset
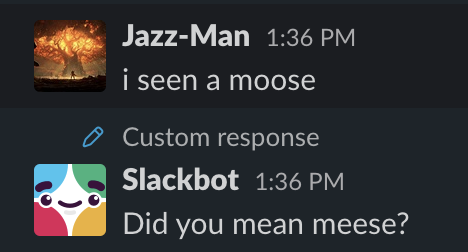
For my dataset, I took the chat history from all of our company’s public Slack channels and added them line by line to a text file. I removed messages from bots that posted meeting times and similar messages that I thought would add too much noise. But I left in messages from our instance of Slackbot that are predefined responses to certain keywords. For example, if somebody includes the word “moose” in a message, Slackbot will kindly offer the correct spelling of the word. I left those in to see how well GPT-2 would pick up on the keyword/response pattern and also to see how well the generated Slackbot responses would stick to the small set of responses that the real Slackbot uses.
I also capitalized every occurrence of a username in the slack data to make them distinct from other words. This helped me to easily identify them in the generated text. Besides that, I didn’t add any extra delimiters to the data because the “<USERNAME>: <POST><NEWLINE>” slack format seemed simple and distinct enough that the fine-tuning should work without wildly misinterpreting the pattern.
Additional considerations
That is not to say a carefully placed delimiter couldn’t have improved the fine-tuning. For instance, something like “<END OF CHANNEL>” between each set of channel history might have made the context of the generated conversations a little more uniform, with less topic switching in a single conversation. And adding timestamps to each message in the dataset might have allowed the model to distinguish between multiple messages in a row that were all replies to one another, and a standalone message from hours later that is on the next line of the dataset. But there’s no way to tell for certain if any of that would have improved the fine-tuning output without actually testing it. These considerations were beyond the scope of this particular experiment.
When dealing with GPT-2 it is important to remember that the model is essentially a black box. It is a pre-trained model and fine-tuning will not alter the underlying architecture. The only way to know what output you will get from a certain input is trial and error. Before fine-tuning with the slack dataset I had a general idea of what sort of results to expect based on other examples of GPT-2 fine-tuning I had seen. This tweet, created by fine-tuning on scripts of The Office, and this site, which generates text trained on Harry Potter and Game Of Thrones books, are two such examples. But for the specific Slackbot cases (responding to a prompt and sticking to a small set of responses) I didn’t have any real expectations, I just wanted to see what would happen.
Results with basic conversations
I let the fine-tuning run for 4,000 steps using the medium sized 355M GPT-2 model with an 8MB slack dataset on an Nvidia T4 GPU until the average loss stopped changing and the model had converged. It took about 3 hours. After fine-tuning, I ran the model 15 times with no input string to get fifteen 250-character length samples of data to compare against the training dataset to check for overfitting. I found no examples of self-plagiarism in the 15 generated strings. Every sentence was unique except for certain keywords and short phrases that were extremely common in the training data.
Some of the generated conversations were surprisingly believable:
ELON: konis is literally the best resturant that has ever existed BILLIAM: https://media.giphy.com/media/iJQzmNrSzWzDtL7NwU/giphy.gif PIGEON LIFE-GIVER: i've been to that 7 times now and its been good every time GAB: it's also the only place in troy that serves dumplings PIGEON LIFE-GIVER: and they are good GAB: they're all good PIGEON LIFE-GIVER: and the chicken parm sandwich is :100: PIGEON LIFE-GIVER: thats not bad JAZZ-MAN: the bread was always super greasy though.
And some were not:
CONKER: trash is the new upholstery CRUSTACEA: there are still many people that dont understand this CRUSTACEA: inyearth has it's own flavor CRUSTACEA: one of our troops PIGEON LIFE-GIVER: Lol
But that’s pretty common for GPT-2, especially for the medium size 355M model that I used. Even the large model usually needs to be run multiple times to get coherent output. The important thing here is that the fine-tuning worked because the output follows the input format correctly.
Results with more advanced message artifacts
The generated slack conversations even use emojis and generate Giphy and other internet links. All the links are fake and, for the most part, there’s no way to tell when a reaction GIF would be appropriate in a conversation. But the links that have embedded words are usually related to the conversation.
CRUSTACEA: did someone say favorire cat? BILLIAM: huh i thought that was just an online thing CRUSTACEA: i forgot about it PIGEON LIFE-GIVER: theres a website you can use to make a list of all the places you could get the cat BILLIAM: looks like a good list management system LADY BOWSER: you should make a free cat website PIGEON LIFE-GIVER: that way i wont have to download it every day LADY BOWSER: https://www.freecat.com/ LADY BOWSER: https://www.freecat.com/us/us/en/cat/product.p?catid=101&loc=1041&pgs=1
While there was some success with emojis and links, the generated Slackbot responses were unfortunately all over the place. They don’t respond to the prompts used in the training set, such as the “moose” example above.
PIGEON LIFE-GIVER: moose, not to be confused with moose, which is just a different kind of horse LADY BOWSER: are there any other food things that can be eaten by horses? LADY BOWSER: like grass and leaves LADY BOWSER: I don't think so CRUSTACEA: I've seen it LADY BOWSER: actually there is LADY BOWSER: I think my horse is just a zombie horse that lives in my basement LADY BOWSER: he's 12 and I just let him roam around and graze in front of my house MURREY: isn't that a Buddhist practice? LADY BOWSER: Yes
And although it often does use responses from the training set, it also will say completely new things.
SLACKBOT: I'll go home and huff some pennies for breakfast
The generated conversations often seem to include responses from “users” who are mentioned by name by another “user.” Without any type of statistical analysis, it’s difficult to say whether this is a coincidence or not.
TIMTAM: SYRUP, you're clearly feeling some stress SYRUP: XD
Take-aways
Adding more data to the training set or strategically placing delimiters could improve upon these results but probably not significantly (based on the performance of the full parameter model). Another option would be to use a better language model. Fine-tuning on the full size GPT-2 model is currently impossible. But GPT-3 has been released privately to select researchers and a public release is probably not far away.
A somewhat-working Slack conversation generator might not have many practical uses when it comes to natural language processing. But, it’s important to have a baseline understanding of the technology. And, it’s important to be aware of its potential applications. This is especially true as its presence in everyday gadgets and software continues to grow. Understanding how and when to work with new tech is essential for producing modern, quality software. And a general awareness of the “tech landscape” is necessary in making informed decisions as a consumer.
Some fun examples for additional exploration
Here’s a few projects I came across that I found interesting and fun. While some use GPT-2, others are already making use of GPT-3.
- Text adventure game (“AI Dungeon”) that uses GPT-3 to generate content. (An older version uses GPT-2.)
- Layout generator that uses GPT-3 to write JSX code from plain-text descriptions.
- Job description rewriter that uses GPT-3 to expand on an otherwise boring job description.
- Code automation plugin (“TabNine”) that uses GPT-2 to help write code faster.



 Strategy for Modernizing Monolithic Applications
Strategy for Modernizing Monolithic Applications
 The "Frankenstein" Cloud Software Application
The "Frankenstein" Cloud Software Application
 A Guide to Custom Software Development
A Guide to Custom Software Development
{kind=link}
{kind=link}
{kind=link}